


Windows
Warum arbeitet dein Windows mit UTC?
Wie ist die Zeitzone bei deinem Kalender eingestellt?
Fragen über Fragen, die immer noch unbeantwortet sind!
Windows
Warum arbeitet dein Windows mit UTC?
Wie ist die Zeitzone bei deinem Kalender eingestellt?
Fragen über Fragen, die immer noch unbeantwortet sind!
Bei mir gibt es nämlich schon Probleme!
Arbeitest du mit Linux? Erzähle doch mal ein wenig. Bisher weiß hier niemand etwas über das Umfeld, in welchem sich dein TB befindet.
Es ist der interne Kalender von Thunderbird!!
Mit dem gibt es auch keine Probleme: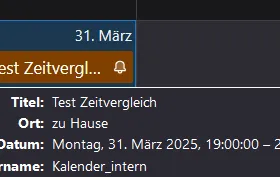
Aber wenn ich heute einen Termin für morgen eintrage, dann kann er doch nicht zu einer falschen Stunde angezeigt werden!!
Der Microsoft-Kalender bspw. erkennt den Übergang von Normal- zur Sommerzeit und umgekehrt bei der Erstellung eines Termins. Bei Google bin ich mir da nicht so sicher. ![]()
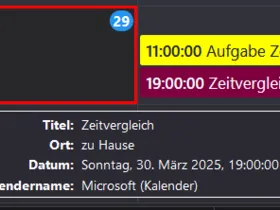
Wie krieg ich das wieder gerichtet?
Ist es ein externer Kalender? Wenn ja, dann schau morgen noch einmal hin. ![]()

Vielen Dank, das wars! Hätte ich nie gefunden...
Ich finde es immer richtig bemerkenswert, wenn Hilfesuchende die "Hilfreichste Antwort" geben. Irgendwie ![]() ! Aber Ok, wenn die Forum-Software solch ein Szenario überhaupt zulässt.
! Aber Ok, wenn die Forum-Software solch ein Szenario überhaupt zulässt.

anbei die Bilder zu den Filtern, wie ich sie eingestellt habe:
Die von dir gezeigten Filter sollten einwandfrei funktionieren. Ich habe diese Situation hier einmal nachgestellt und ein wenig experimentiert.
Alle versendeten Mails über GMX landen so auch als Kopie in den "Gesendet"-Ordner des Kontos "lakl@home.local". Alle reinkommenden Mails (GMX) landen auch als Kopie im Posteingang von "lakl@home.local". Das ist doch das, was du wolltest.
Sind vielleicht noch andere Filter im "Spiel"?
Vielleicht hat doch noch jemand eine Idee was ich falsch mache.
Zeige uns (Bild) zunächst den bzw. die Filter, welche du angelegt hast.

Ich hoffe, ich habe es verständlich erklärt.
Kannst du dein Problem bitte zum besseren Verständnis mit Bildern darstellen? Danke

Aufgrund der Einstellungen in Ihrem Screenshot habe ich für GMX nun auch noch mal die alternative Möglichkeit der "SSL"-Verschlüsselung an Port 465 probiert und siehe da: Es funktioniert. Freenet analog auch.
Das deutet darauf hin, dass dein Handy nicht über die aktuellen SSL/TLS-Bibliotheken verfügt. Was ist es denn für ein Handy und über welche Android-Version verfügt es?
WEB.de ist eigentlich nichts anderes als GMX - einst waren sie "Schwestern". Man sieht es auch noch an dem Aufbau der WEB-Seiten. Auch die Server-Einstellungen sind bis auf die Namen jener Server identisch.
Hast du bei WEB.de vielleicht eine zweistufige Anmeldung vereinbart?
Gerne.
Auch deine Server-Einstellungen (StartTLS, Port 587) funktionieren hier "auf Schlag" ohne Probleme. Ich vermute bei dir immer noch einen "Blocker".
... App-spezifische Passwörter ....
Ein solches Passwort ist bei deinen Einstellungen eigentlich nicht notwendig.

Wenn ich einen mailto:-Link (aus Webseite oder PDF) öffne, bekomme ich ein Entwurfs-Fenster in dem keine Von-Adresse eingetragen ist.
Zeige uns den Editor im Vollbildmodus!
Deine gezeigte Situation ist für jedermann nachvollziehbar, wenn das Editorfenster zu klein aufgezogen ist!

Ich habe nun auch im Problem-Profil einen neuen Schlüssel erzeugt. Dann geht es.
Prima! ![]()
Die Frage ist ja nun, wie man die interne Schlüsselverwaltung zugunsten einer externen (Kleopatra) aufgibt ...
Dieses ist mit einigen Schritten schnell erledigt:
Import externer geheimer Schlüssel: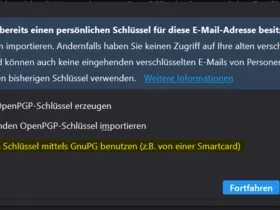
Nach dem korrekten Import wird bei verschlüsselten Mails wieder nach der Passphrase gefragt! ![]()
Weiteres Thema: Weder die interne Schlüsselverwaltung noch Kleopatra ermöglichen das Erzeugen eines Widerrufszertifikats ohne dieses sofort hochzuladen.
Nun ja, ansonsten ergibt ein Widerrufszertifikat ja auch keinen logischen Sinn.
Viel Erfolg! ![]()
Nein. Es sei denn Samsung liefert serienmäßig irgendetwas mit, was ich noch nicht entdeckt habe...?
Ok. Könntest du bitte einen Screenshot der Daten des Postausgangsservers (SMTP) zunächst nur von GMX liefern? Wir sollten einmal "en Detail" vergleichen.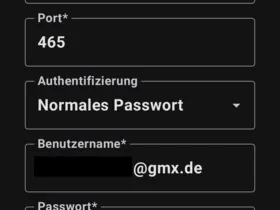
In meinem anderen Profil funktioniert es nun - und ich weiß nicht, warum. Dort ist es ein anderer Schlüssel. Dort wird die Passphrase in der Tat bei Benutzung nicht abgefragt.
In deinem Screenshot sieht man, dass auch für S/MIME Schlüssel vorgesehen sind. Für einen Test bezüglich GnuPG sollte man zunächst die S/MIME-Schlüssel nicht aufnehmen und diese erst hinzufügen, wenn die Signierung/Verschlüsselung mit GnuPG reibungslos funktioniert.
Allerdings sollte es auch mit der Kombination aus GnuPG und S/MIME keinerlei Probleme geben. Da GnuPG nun in einer anderen Installation bei dir funktioniert, ist ein Hinweis darauf, dass bei dem Import der Schlüssel etwas schiefgelaufen sein muss.
Hinweis:
Wie du nun selbst erleben darfst, hat die interne Schlüsselverwaltung den erheblichen Nachteil, dass verschlüsselte Nachrichten grundsätzlich in Klarschrift dargestellt werden, was u.U. nicht gewollt ist (jemand steht hinter dir oder hat gar Zugriff auf deine TB-Installation).
Da sämtliche drei Postfächer betroffen sind, scheint es mir ein grundlegenderes Problem zu sein..?
Ich nutze Android-Version 14 und die K9-Mail-Version ist 9.0.
Das Problem tritt sowohl im Mobilnetz als auch im WLAN auf.
Hast du irgendwelche Virenscanner oder andere "Blocker" in Form von Sicherheitssoftware auf deinem Android-Gerät?

Aber es ist natürlich richtig, etwas was nicht verlässlich funktioniert kann man nicht empfehlen. An dieser Stelle muss ich TB mal ein mangelhaft geben.
Persönlich beobachte ich immer wieder, dass die User einem Add-On mehr Vertrauen schenken als bspw. ihrem Windowsexplorer oder unter Linux einem Dateimanager.
Für dich sollte doch solch ein Add-On (Easy-Backup ![]() ), welches "einfach nur" das aktuelle Profil komplett (1:1) in ein vom User vorgegebenes Verzeichnis kopiert, Spaß an der Freude sein.
), welches "einfach nur" das aktuelle Profil komplett (1:1) in ein vom User vorgegebenes Verzeichnis kopiert, Spaß an der Freude sein. ![]()

Hier der screenshot
Was verstehst du unter einer Neuinstallation in deinem ersten Beitrag? Gab es schon ein Profil, mit welchem gearbeitet wurde?
Wo hast du die Version 136.0.1, welche dir ein Hauptpasswort abverlangt, heruntergeladen?

b.) Eine Größe des Profil-Ordners von 12 GB ist ja wohl auch zulässig - oder?
Nein! Für den Export eines Profils über das Menü "Exportieren" gelten maximal 2GB!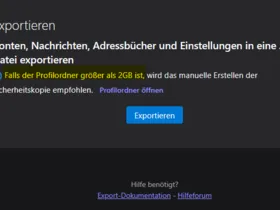
Ich nutze PGP /GPG seit ca 20 Jahren.
Ok. Allerdings sind deine momentanen Probleme (siehe Bild1 in #3) absolut nicht nachvollziehbar.
... und dabei auch einen neuen (den 0FD7) angelegt habe.
Nochmal:
Wurde dieser Schlüssel in TB korrekt hinterlegt (Bild)?
Hast du dir mit diesem Schlüssel schon eine Test-Mail an dich selbst gesendet und wurde diese Mail korrekt entschlüsselt und verifiziert?